![Autonomo]()
El mercado laboral en la industria del desarrollo de software, está que arde. Las empresas se enfrentan diariamente a la frustrante búsqueda de perfiles técnicos que, simplemente, no existen en número suficiente como para cubrir la demanda.
Sin embargo, el establecimiento y fomento de una industria basada en las horas vendidas “al peso”, por la continuada permisividad del estado ante el constante infringir de las leyes de cesión de trabajadores, ha influido con fuerza en el crecimiento de la vía del autoempleo. En donde el programador toma las riendas y riesgos de su profesión, y se establece como trabajador autónomo por cuenta propia.
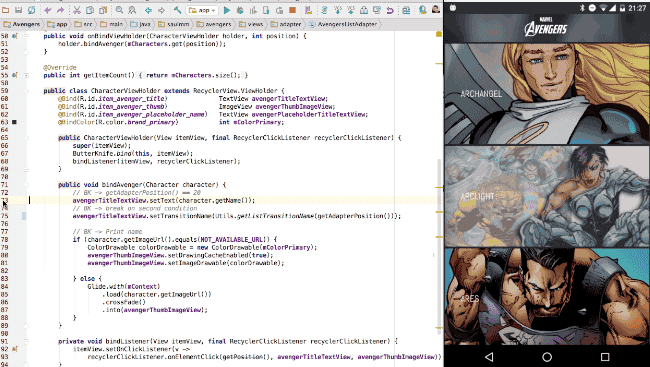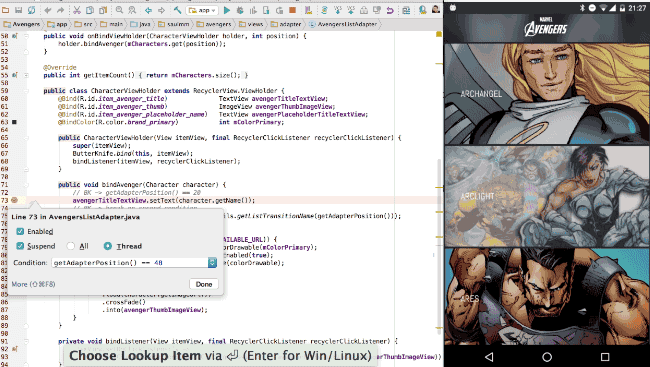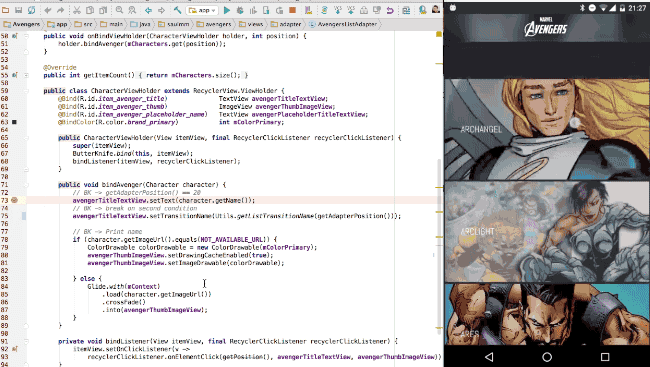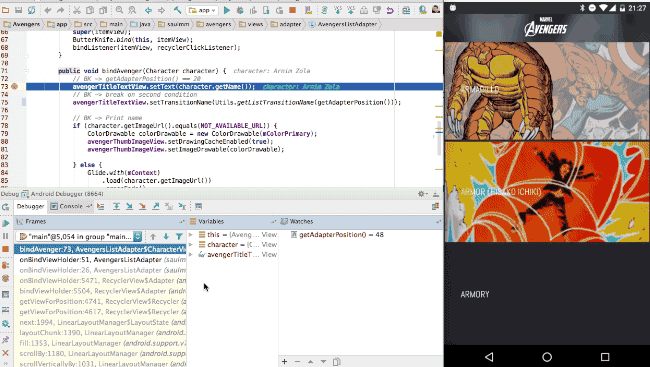
Para hablar sobre este tema he organizado una mesa redonda (HangOut) en donde nos reunimos cuatro amigos a compartir nuestras experiencias como trabajadores autónomos de la informática, desde puntos de vista diferentes.
Y de esta entrevista colectiva, han surgido ideas que quiero compartir contigo, lector de Genbeta Dev.
Me acompañaron en la mesa redonda…
![Genbetadev Autonomos]()
Sergio León
Desarrollador web de soluciones basadas en tecnologías Microsoft.
Miembro activo de la comunidad .NET, mantiene regularmente un blog de desarrollo.
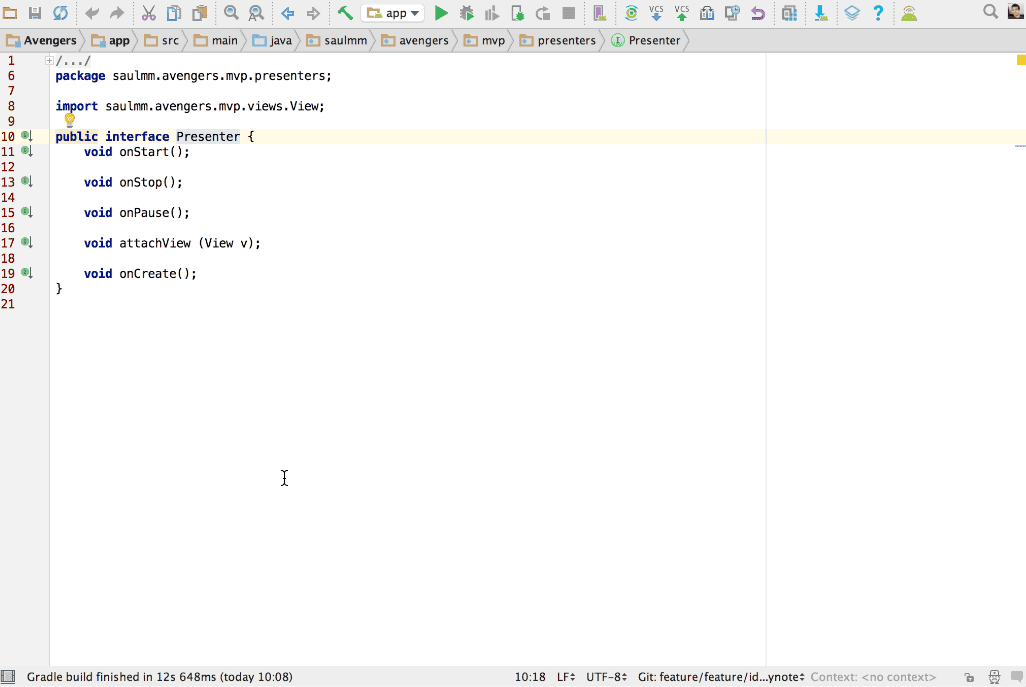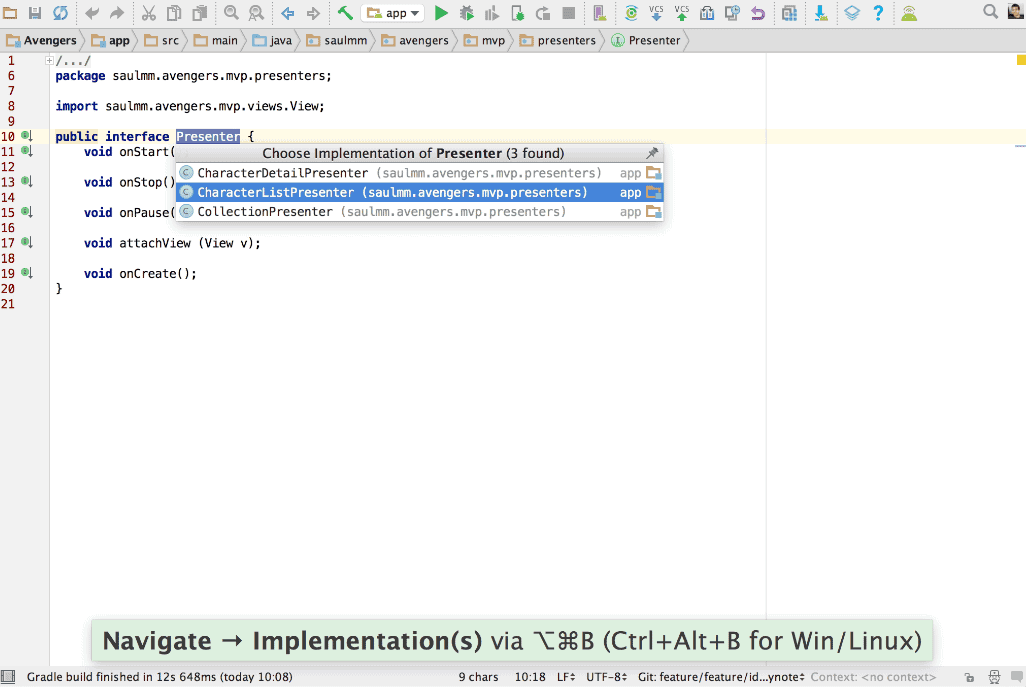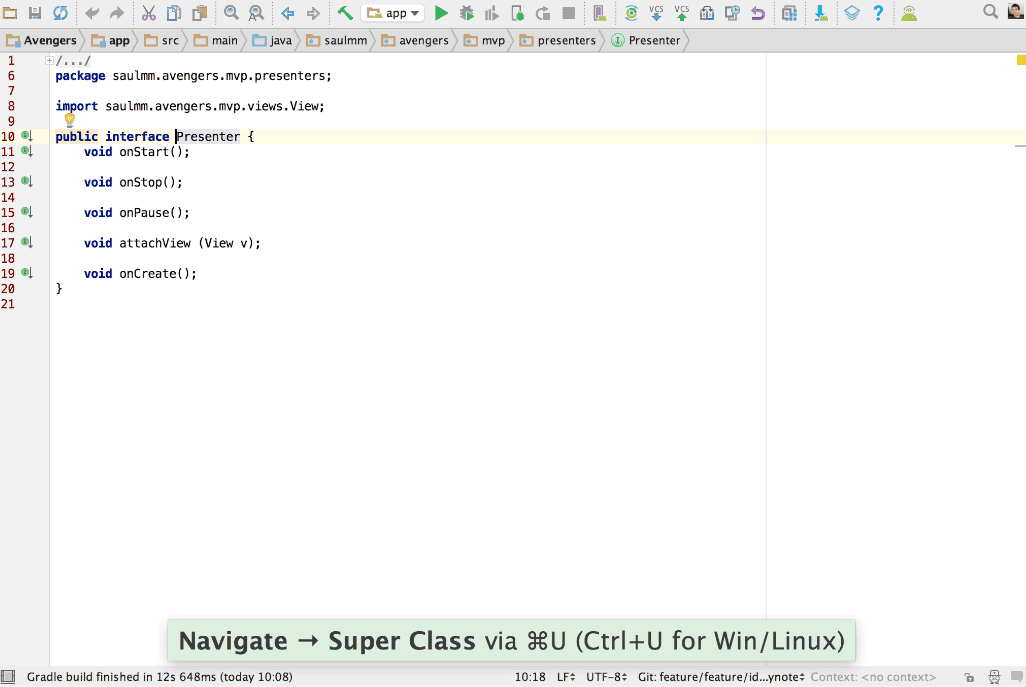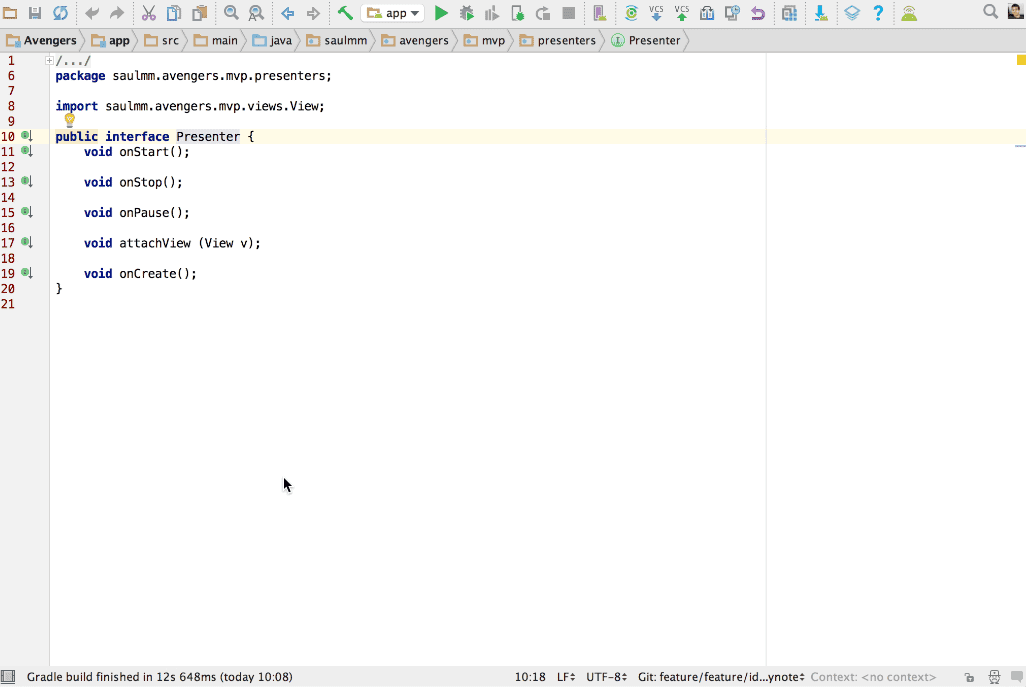
Lo que más le gusta es compartir y aprender.
twitter @panicoenlaxbox
blog http://panicoenlaxbox.blogspot.com/
Sergio tiene experiencia en más de una década como autónomo, llegando a tener trabajadores contratados en su equipo. Ahora mismo está en una etapa nueva cuando se ha integrado en uno de sus principales ex clientes, aportando a la mesa redonda la visión de quien recién ha vuelto a trabajar por cuenta ajena.
Pedro J. Molina
18 años desarrollando Software y especialmente enfocado en Software de Modelado y Generación de código. Es Ingeniero y Doctor en Informática por la Universidad Politécnica de Valencia donde realizó investigación en Ingeniería del Software. En los últimos 5 años ha sido Director de I+D y CTO para Icinetic en Sevilla y Seattle donde ha participado en los productos: Radarc, Windows Mobile AppStudio, Buildup.io o Hivepod.io.
Esta especializado en Microservicios, backends y despliegues en nube; además de dar ayuda a los equipos de desarrollo a mejorar y optimizar sus procesos para ganar en agilidad y mejorar la calidad del software.
Twiter: @pmolinam
Pedro aporta la visión del némesis de Sergio. Siempre con puestos de responsabilidad en empresas, ahora está preparando el salto a ser su propio jefe y tomar su propias decisiones y riesgos. De forma planificada, meditada y con una potente visión empresarial.
Roya Chang
Desde hace años la gente suele llamarla "incombustible". Quizás sea porque, a sus 26 años, ha trabajado como profesora, estilista o incluso intérprete de chino para la Policía Nacional; además de sacar el título como Ingeniera Informática. Su amor por la tecnología la ha llevado hasta grandes empresas como Microsoft, trabajando en el rol de Evangelista Técnico responsable de los programa para estudiantes y contacto con universidades y centros educativos o BQ, como Product Manager en I+D de software.(www.flexcomtec.com/flexbot). Puedes contactar conmigo a través de mi Twitter: @RoyaChang
Roya, actualmente trabaja como desarrolladora freelance Full-Stack.Creando su propia línea de Electrónica y robótica educativa para colegios. Está recién iniciada en el autoempleo, enfrentándose a las complejidades del sistema para ser autónoma, con un empuje e ilusión que se apoya en su juventud. Aporta una visión de cuando estaba integrada en grandes multinacionales en relación a trabajar para uno solo. Además de resaltar la importancia de la inteligencia emocional imprescindible para lanzarse al ruedo.
¿Qué hay que hacer para entrar?
![Puertas De Entrada]()
Lo primero que debes tener meridianamente claro es que tus circunstancias personales y profesionales sean positivas para ello. Como comentábamos en la mesa redonda, el autónomo nace con la inquietud y con el arrojo necesario para “buscarse la vida”, pero se hace con experiencia laboral previa y mucho estudio.
Lo que quieres hacer te debe apasionar y ser tu hobbie. Es decir, que no te duelan prendas el tener que dedicarle todo o casi todo tu tiempo libre. Porque, si no es así (como puede pasar en un trabajo por cuenta ajena), tu labor diaria se puede convertir en un infierno.
También es crítico que tu entorno y, sobre todo, tus compañeros vitales (pareja, padres, etc.) estén plenamente de acuerdo y dispuestos a echarte una o dos manos en tu emprendimiento. No tanto de forma activa, es decir apoyando positivamente la nueva posición laboral, sino teniendo cuidado de no “trolearte”: convertirse en un lastre o impedimento que te obligue a elegir.
Es imprescindible tener un apoyo emocional y moral en las personas de tu alrededor que van a sufrir tanto las alegrías, las penas y las tensiones al tomar el control de tu trabajo.
-- Roya Chang
Pedro J. Molina también señalaba la importancia de preparar una estrategia de ventas y marketing. El decidir cuáles van a ser las apuestas de valor que te van a diferenciar del resto de la competencia (que es bastante dura). Y qué recursos económicos vas a poder disponer en el mejor y en el peor de los casos.
Cuanto mejor lo lleves pensado, más posibilidades tienes de tenerlo previsto. Aunque luego la realidad deja casi siempre en agua de borrajas nuestras predicciones, y es necesario desarrollar una cintura ágil y mucho teflón para que te resbalen las preocupaciones y no te bloqueen.
Hacienda somos todos
![Ministerio De Hacienda]()
Como todo vecino en este país, lo primero que debes hacer para empezar a trabajar como autónomo es pagar. Pero si es tu primera vez, o llevas más de 5 años sin haberte dado de alta, puedes solicitar la “tarifa plana” que ofrece los siguientes descuentos:
- Primeros seis meses: se paga una cuota fija de 50 euros mensuales, lo que supone un ahorro de 209,13 € sobre la tarifa normal. Esto es así si el autónomo elige su base de cotización mínima. Si elige otra mayor, tendrá una reducción del 80% de la cuota.
- Del mes 7 al 12: una reducción del 50% (ahorro de 129,57 €)
- Del mes 13 al 15: una reducción del 30% (ahorro de 77,74 €)
- Del mes 16 al 18: una reducción del 30% (ahorro de 77,74 €)
- Del mes 19 al 30: se mantiene una reducción especial del 30% (ahorro de 77,74 %), que no hayan sido autónomos en los 5 años anteriores.
Además, una vez iniciado los trabajos, vas a tener que hacer la declaración del IVA cada tres meses, en donde deberás abonar el IVA de todas las facturas emitidas durante ese periodo lo hayas cobrado o no. Sí, es esa la broma pesada del pago adelantado del IVA.
También tienes que hacer la declaración de Beneficios anual (ingresando en Haciendo un 30% de los mismos), y llevar al día todo el tema de las cuentas.
No delegues sin supervisión. Una mala praxis te puede meter en un “pufo importante”.
-- Sergio León.
Por todo ello, todos los presentes en la mesa redonda estábamos plenamente de acuerdo en que es imprescindible el buscar y contratar una buena gestoría. Y si, además, lo juntas con un buen despacho de abogados, tendrás cubierto un aspecto crítico de tu trabajo.
No lo intentes llevar tú porque, en la mayoría de los casos, termina en un caos que desemboca en sanciones por parte de los organismos gubernamentales recaudatorios.
Sin embargo, aun delegando en profesionales del sector, no te desentiendas del todo de los asuntos administrativos y legales. Debes de hacer el seguimiento y tutelaje de las operaciones porque, finalmente tú y solo tú, eres el último responsable.
Por último, como consejo, asegura que las incidencias económicas y legislativas que pudieran surgir de tu acción laboral, no impacten sobre los bienes de tu familia y la gente más cercana. Salvaguardando así el “bote salvavidas” que necesitarás si las cosas van mal o muy mal.
La satisfactoria dura realidad
![Realidad Dura]()
Bueno ahora ya eres autónomo, eres tu propio jefe y tienes el control absoluto de tu tiempo. Ahora debes de tener muy en cuenta los principales riesgos que te pueden llevar a salir corriendo en busca de un medio de supervivencia. Y con los cuales todos nos hemos tropezado en mayor o menor grado.
El primero es justamente el trabajar demasiado. Está claro que todo desarrollador tiene a un Mister Hyde en su interior que le empuja a seguir codificando durante horas, sufriendo y padeciendo hasta llegar al orgásmico momento en que todo funciona.
Y también es cierto que tenemos a un Jekyll que nos empuja suavemente al caos, al último momento de máximo agobio y a esos esfuerzos hercúleos para poder cumplir el plazo acordado con un cliente feroz o – aún peor – con nuestras propias e irreales fechas de entrega.
Para ello, como bien dice Roya, es imprescindible una organización y disciplina férrea. El hacer de habito el trabajo, sin permitir que el que esté en el hogar me lleve a trabajar en pantuflas y pijama, con todos los riesgos de ostracismo y alejamiento de la realidad que conlleva largos transcursos de tiempo sin una conversación cara a cara con humanos.
Recuerda y tener muy presente que se trabaja para vivir y no al revés. No permitas que lo urgente te arrebate lo importante, defiende el espacio vital que requiere tu salud mental y la gente que tienes a tu alrededor que te apoya y te da estabilidad emocional y moral. Y aquí cobra especial importancia esa pareja que te “obliga” a salir del zulo en donde estas 16 horas al día, y compartir el tiempo con las personas que te quieren y te aprecian.
Otro factor de gran importancia es ser extremadamente estricto con los gastos de la empresa. No los confundas con tus gastos personales, ni tengas el dinero mezclado en la misma cuenta. Recuerda que el IVA no es tuyo, y que tu único sagrado propósito para Hacienda es transmitir ese dinero en las declaraciones trimestrales.
Y prepárate para los llamados “gastos extraordinarios” que, como bien dice Sergio León, son inesperados, insospechados y abundantes.
Venderte no es opcional, es crucial
![Venderse]()
La mayoría de los programadores que conozco tiene un conocimiento pobre sobre las complejidades de vender, del trabajo de un comercial e – incluso – de la utilidad del rol. Pero eso se va a acabar en cuanto empieces a trabajar como autónomo, porque el trabajo no viene a llamarte a la puerta de tu oficina/casa más que en casos extraordinarios.
Por ello es imprescindible hacerte una buena y sólida imagen de calidad en Internet, y en todos los medios posibles. Incluso dedicar tiempo a labores de preventa y prospección, restándole del dedicado a picar código y hacer cosas productivas.
Hacer networking es obligatorio, y por ende el asistir a los eventos de la comunidad o de los círculos de tus clientes es obligatorio. Es más, deberías ir más allá del mero partícipe y convertirte en ponente o patrocinador, para darle un empaque más profesional a tu experiencia. Además, es el sitio excelente para aprender y ser consciente de las cosas que te quedan por estudiar o ponerte al día.
Dedica tiempo a aprender, a mejorar y a compartir tu conocimiento. Huye del acomodo que se produce cuando tienes controlada una herramienta o una tecnología. Y mantén siempre viva la llama de la curiosidad y la inquietud por conocer y explorar nuevas formas de abordar los retos.
“Si eres autónomo y no ganas dinero, algo estás haciendo mal”. Sergio León
También debes tener un precio por tu trabajo que te permita vivir holgadamente. Como indica Sergio León:. Debes tener presente que, sobre el coste de la hora que te puede permitir un sueldo “decente”, debes sumar los impuestos, algún tipo de protección frente a las bajas por enfermedad o accidente, los tiempos muertos sin trabajo (que no se cobra), las vacaciones, tu jubilación, la reinversión, el crecimiento de la empresa, los gastos corrientes, y los benditos imprevistos.
O sea que cobrar 3.000€/mes bruto es ir casi al límite de la mendicidad. No estás preparando nada para el futuro, y el presente debe ser perfecto para no encontrarte con serios problemas económicos en cualquier momento.
Pero para llegar y superar holgadamente esas cifras, deberás ser especial y especialista. Demostrar que, en tu sector, eres el mejor o uno de ellos. Y para eso hay que luchar por ser bueno o muy bueno en el nicho de mercado en donde vas a centrar el tiro, y tus esfuerzos.
Recuerda que al autónomo se le supone mucha capacidad de ser proactivo y que no se le pasa una. Cuan cierto es el dicho que dice: “Mil horas para ganar un cliente, un minuto para perderlo”. Y a sus conocidos, añadiría yo.
Los principales peligros en la selva del autónomo.
![Selva]()
En la selva de los autónomos hay mucho peligros y obstáculos que pueden llevar a un mal termino la aventura laboral por cuenta propia. Y de entre ellos quiero destacar tres en especial que tienen una incidencia importante en los motivos del fracaso.
El primero es el peligro económico de morir por asfixia económica, y que es principalmente motivado porque en España se paga tarde y mal. Este país debe tener una de las legislaciones de impagados más laxas del mundo, en donde todos los estamentos – privados o estatales – se basan en la presunción de que nadie paga según lo convenido; y si se puede, pues terminan por escaquearse de pagar.
Es paradójico que cuanto más grande sea la empresa deudora, más tarde paga, y más obliga a soportar los gastos financieros al proveedor. Incluso se llega al obsceno caso de que pagan tan tarde, que te ofrecen sus propios servicios financieros que adelantan lo que te deben por una comisión sobre lo que ellos te deben. O, el vergonzante ejemplo del estado y sus plazos de pago de uno, dos o tres años para abonar lo que se debe; a lo que se añade el chantaje de “no te doy nada más” si te atreves a plantear una demanda por vía judicial.
Otro problema muy serio es cuando te resistes o no tienes talento para las labores comerciales. Es decir, no creces porque no te vendes. Y no te vendes porque no tienes tiempo. Y ese circulo vicioso te lleva a abandonar tarde o temprano por asfixia o cansancio.
También existe la vertiente más sibilina en donde tienes un cliente del que depende la mayoría de tu facturación y que termina devorándote y haciéndote una oferta como trabajador a cuenta ajena; o desaparece obligándote al cierre por quiebra (esto último lo he vivido en primera persona).
Y la última, e ilegal, sucede cuando este cliente se convierte en el único. Para el cual trabajas con todas las obligaciones de un trabajador por cuenta ajena, y con todos los inconvenientes y riesgos de un trabajador por cuenta propia. Y sin ningún derecho.
Eso que se denomina “falso autónomo”. Y que puede durar décadas hasta que un imprevisto te hace ver de forma cruda lo inconveniente de esta situación para el trabajador.
Buscando la salida
![Salir]()
Ha llegado el momento. Ya sea por qué no puedes seguir, no quieres seguir o has crecido tanto que debes montar una empresa,** la cuestión es que vas a dejar el régimen de autónomo en busca de nuevas formas** de relaciones laborales. Y en ese momento verás como terminas como empezaste: pagando.
Recuerda, una vez más, que el IVA no es tuyo. Por lo cual cierra bien el último trimestre de la declaración para dejar saldadas todas las deudas que pudieras tener con la administración. También señala con fuego en el calendario la fecha de la declaración de Beneficios y tu próxima declaración de Hacienda que siempre sale a pagar.
Es decir, asegúrate que nada del pasado pueda aparecer en el futuro para amargarte la vida con responsabilidades no cubiertas. Y que, además, llegaran multiplicadas por comisiones de demora, premura, costes financieros y judiciales.
Si vuelves a ponerte en búsqueda activa de empleo a cuenta ajena, prepárate para que tus años de experiencia no tengan la validez que esperabas. Cuenta mucho más tu imagen en la Red y tu reputación en la comunidad, que los trabajos que hayas realizado. De hecho, volver al mercado laboral produce desasosiego y se puede hacer una tanto complicado si no tienes bien preparado el Currículo y las entrevistas.
En cambio, si lo que haces es crecer hacia convertirte en una empresa, los riegos y los beneficios se multiplican y nos salimos absolutamente del ámbito de este artículo. Por suerte hay mucha literatura para emprendedores y el emprendimiento. Alguna muy buena, pero cuidado con la morralla centrada en la autoayuda y en hacer negocio con las ilusiones de las startups.
Pero entonces, ¿por qué hacerse autónomo?
![Exito]()
Puede dar la sensación que este artículo hace hincapié en las dificultades y riesgos del trabajo por cuenta propia. Pero no es así. De hecho, el espíritu al escribir este post es el animar a aquellos que sientan que es el momento para encontrar su propio camino, el lanzarse al ruedo y coger el toro por los cuernos.
No hay mejor manera de explicar con una sola frase, el sentimiento que te lleva a buscar tu propio camino y seguir tus decisiones, después de años trabajando para los demás. Para bien o para mal. Pero con la certeza e ilusión de quien conoce en profundidad el mercado, el negocio y la industria.
“Esta vez no va a ser culpa de mis jefes. Esta vez la culpa va a ser mía”.
-- Pedro J. Molina
A Roya Chang le motiva que sus proyectos personales vean la luz, le fascina y le encanta la robótica educativa y lucha por un futuro en donde la infancia acceda de forma natural a la programación, convirtiendo a España en un país puntero en el sector del desarrollo de aplicaciones informáticas.
Y Sergio León, la voz de más de una década de experiencia, rezuma nostalgia de los tiempos de autónomo en que “vivía muy bien”, aun cuando su puesto de responsabilidad actual, a cuenta ajena, represente nuevos retos, satisfacciones y oportunidades.
Sin duda el cimiento básico que ofrece trabajar para uno mismo, es el tener el control de tu vida laboral. El ser “diferente” a la generalidad de la sociedad y apostar tus conocimientos y esfuerzos para alcanzar una calidad de vida superior a la media.
Todos en la mesa redonda, incluyéndome, estuvimos de acuerdo en que el ser autónomo es algo positivo y que debiera ser una experiencia personal que todos debiéramos vivir.
Y así obtener el reconocimiento que más difícil es de alcanzar: el propio.
También te recomendamos
¡Concurso! Tus momentos WTF tienen premio: un Xiaomi MI5 o uno de los 25 WTF Smart Sticker pueden ser tuyos
Los 17 momentos por los que merece la pena ser desarrollador
Estado actual de la profesión de desarrollador en Europa
-
La noticia Desarrolladores metidos a emprendedores: ésta es su historia
fue publicada originalmente en Genbeta Dev
por
Juan Quijano
.
![]()












 en el sentido de que los segundos adquieren "las malas costumbres y pensamientos impuros" de los lenguajes imperativos (permíteme que insista con la serie
en el sentido de que los segundos adquieren "las malas costumbres y pensamientos impuros" de los lenguajes imperativos (permíteme que insista con la serie 

 Con cierta frecuencia me llegan preguntas sobre "cómo formarse en calidad de software", "qué cursos o master se pueden realizar", o "qué debería estudiar o hacer para conseguir un puesto como QA Tester". La verdad es que no es una pregunta sencilla. Casi cada especialista que conozco en pruebas de software ha tenido una trayectoria laboral diferente, y lo mismo es aplicable a su formación.
Con cierta frecuencia me llegan preguntas sobre "cómo formarse en calidad de software", "qué cursos o master se pueden realizar", o "qué debería estudiar o hacer para conseguir un puesto como QA Tester". La verdad es que no es una pregunta sencilla. Casi cada especialista que conozco en pruebas de software ha tenido una trayectoria laboral diferente, y lo mismo es aplicable a su formación.